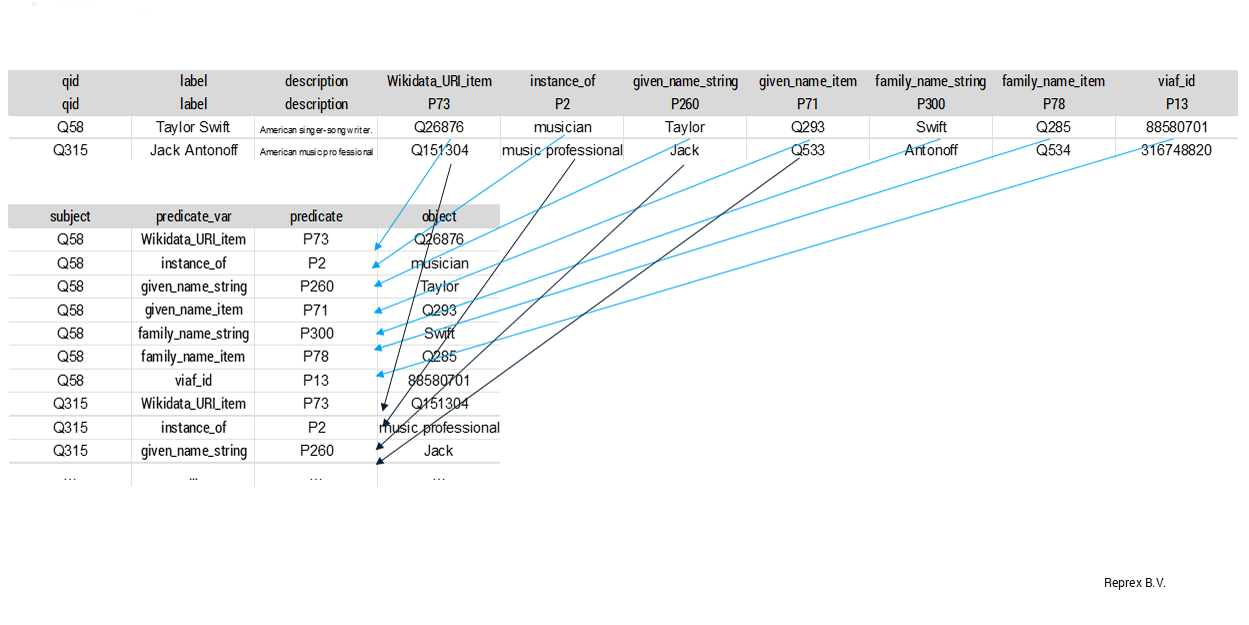
In the Chapter 2 chapter on tidy data we have shown one of the advantages of a tidy dataset: it can be pivoted into a sequence of triple-form semantic statements. This is possible because tidy format is unambiguous: we always know that a number or string (value) belongs to its observational subject (in the rows) and the measured property variable (in the columns). In other words, the meaning of a cell is unambiguous, because we know the subject (from the rows) and the predicate (from the column headings.)
In the Chapter 3 chapter we have seen that naming is hard. Weather we are talking about people, objects, or table variables, it is difficult to come up with good names. Most programmers and open-source communities apply variable naming conventions.
We apply the snake case convention, which creates variables like given_name_string. We make these names tidier with grouping semantic elements into the beginning or ending of the variable name; this way the variable name can be filtered easily.
When importing into Wikibase, we need to know what should be the type of the imported data. Shall we use a string for Taylor and Swift, or we want to create an entity for the name (variants) of Taylor?
7.1.1 Correspondence
Applying dual headings can help to map your column variables into Wikibase properties easily while pivotting into longer format.