2 Tidy work
Все счастливые семьи похожи друг на друга, каждая несчастливая семья несчастлива по-своему.
All happy families are alike; each unhappy family is unhappy in its own way.
Our OpenCollections systems are complex system which are intended to be used in trustworthy AI applications. They follow the Anna Karenina principle: a deficiency in any of a number of factors dooms an endeavour to fail. Consequently, a successful endeavour (subject to this principle) is one for which every possible deficiency has been avoided.
Once the data is messy, there is a semantic ambiguity (an ambiguity in the intended use or meaning of data) that will render automation impossible or will lead to logical faults when software agents or algorithms use your data. You must keep your numeric and text data tidy at all times. The best way to keep data and text tidy is to keep it simple. Very simple.
Simplicity is simple, if you start simple and keep it that way. Simplifying messy text and messy data is always challenging.
Collective work involving data and data annotations and descriptions requires a shared understanding of the syntax and file formats.
Our curators need to be familiar with two ideas.
2.1 Tidy data
Our data stewardship must follow the tidy data principle, which has very complex computer science and information management consequences, but for the curators of data, it boils down to an organised simplicity.
Tidy data is a standard way of mapping the meaning of a dataset to its structure. A dataset is messy or tidy depending on how rows, columns and tables are matched up with observations or collection items, and the measures and types of variables.

Tidy data is a statistical formulation of the Third Normal Form (3NF) defined in 1971 by Edgar F. Codd, an English computer scientist who invented the relational model for database management. It avoids duplications of the data, various data anomalies and misunderstandings, and the integrity of the “place” of the data in a database–be it a tabular or relational database or a graph database like Wikidata. When working with semi-automated knowledge graph management, the automated part is reading the already tidy data into a graph system. What often requires human ingenuity or just simply hard work is to tidy data that was recorded in an untidy way.
In tidy data:
A tidy dataset is black-and-white, and each table cells contains one element of knowledge that cannot be further divided.
We repeat in negative terms these seemingly simple principles:
The exact, mathematically precise explanation of the 3NF data is difficult to understand. Intuitively, it boils down to two important characteristics. It minimises data duplication, and therefore the possibility of data contradicting itself (the same data was updated in one cell, but not in the other as new information came to light.) The other, even more important characteristic is semantic clarity: the second row of the second column can be interpreted on its own; there is no asterisk, little arrow, or yellow highlight; if there was, than we would have to ensure that the asterisk, the little arrow or the yellow highlight is also well understood and updated whenever new information comes to light.
Tidy data is easy to understand and makes errors like contradicting information or missing data easier to spot. It is easier to understand well and rewrite tidy data than not-tidy data.
Looks easy? If you start with a tidy table, it is very easy. If you have to tidy up a messy data table or an entire database, it often requires many years of data-wrangling experience to get it right first.
Is there science behind this? Yes, and it is more complicated than it sounds. In computer science or algebraic terms, you must organise your data to Codd’s 3rd standard form. If you start from a well-organised table, it is a piece of cake to keep it that way. Reorganising messy information into a tidy format requires a lot of experience. Understanding that the ambiguity in the meaning of 96-98 should be resolved by treating them as two separate values, one meaning minimum possible length and the other maximum length, will not come naturally for everybody. But we will help in those cases.
2.1.1 Wide & Long Formats

The tidy format is unambiguous: we always know that a number or string (value) belongs to its observational subject (in the rows) and the measured property variable (in the columns). Because the meaning is unambiguous, it can be transposed to different formats without loss of knowledge or misunderstandings.
Our knowledge base applications and Wikibase requires the three-column semantic triple format, because it can be organised into a graph; relational database managers usually prefer the wide format, because in this case every observed property of a data subject is in one record.
A tidy dataset is black-and-white, and each table cells contains one element of knowledge that cannot be further divided.
If your table is tidy, it will be easy to reuse in relational or graph database, or it can import easily into a spreadsheet or statistical program. Any further formatting with colours, divided columns, merged rows will stop the data portability, because only you will know why columns or rows are merged, divided, or coloured.
2.2 Markup text
We create interconnected, interoperable (web) resources. We want to ensure that our research results are findable, accessible, and reusable. It must work in Word and Works, Notebook and VIM, Windows, MacOS, and Linux, with Latvian, English, Greek, and Thai character sets.
The World Wide Web has been a source of high interoperability and findability in the last 30 years, with the introduction of the HTTP protocol and the standardization of the HTML text markup language. We use a much-simplified version of HTML called Markdown.
Markdown text opens on MacOS, Windows, or Linux. It is very easy to translate into HTML, Word, Libre Office, Google Docs, LaTeX, or PDF. Markdown is a simplified HTML text notation that works well with word processors.

If you want Word output, Word is rendered instead of HTML. You can also create a PDF or EPUB and even a PPTX output.
2.2.1 Markdown editors
There are countless Markdown editors. Because Markdown is so simple, you can, if you want to, edit markdown files in Notepad, WordPad (Windows) or VIM (Linux).
Most word processors support markdown. For example, Google Docs has a free extension that converts and document from Docs to markdown.
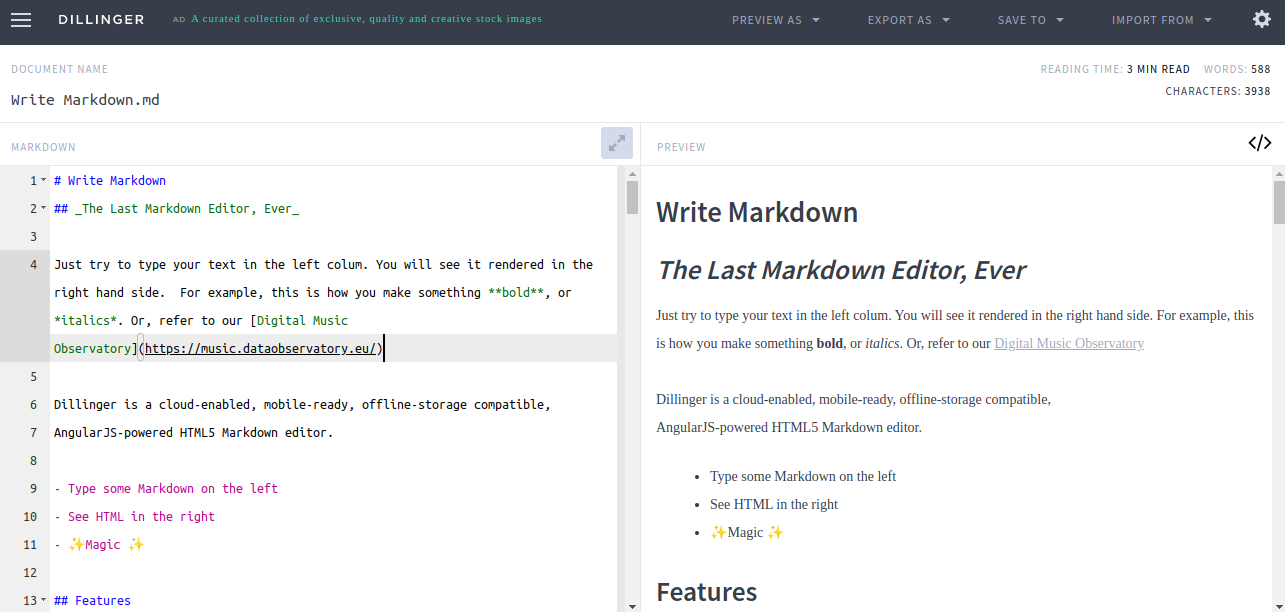
There are several online Markdown editors that you can use to try writing in Markdown. Dillinger is one of the best online Markdown editors. Just open the site and start typing in the left pane. A preview of the rendered document appears in the right pane.
You can work on Word, your iWorks suite, or any preferred word processor. However, you will lose margin settings, font typefaces and sizes, background colors, and other finishing touches.
We discourage the use of word processors for footnotes and bibliographic references due to their varying treatment of such metadata. Our systems rely on standard BibLatex bibliographic references and a simple notation for footnotes, ensuring consistency and reliability.
Our recommended markdown editor is Quarto. You can copy and paste text from Word or other word processors into Quarto, and it will retain bold, italics, and headings.
Remember, we want to create text that machines and people can read, too, to avoid fancy aesthetics. Keep the text fancy (but of course, you can dress it up in Word or Adobe Illustrator later).
2.2.2 Wikipedia & MediaWiki
The documentation of our knowledge base and terminological agreements is documented in MediaWiki, the software that makes Wikipedia editable, too. It uses a form of markdown for an interoperable and simple editing of interlinked documents, images, and data documents.