6 Reprex’s Sandbox
6.1 Create an Account
Depending on the type of MediaWiki+Wikibase instance you are using, you may need to create an account to access the site. The process may be less or more strict, depending on how much private data the instance holds.
Access Reprex’s Sandbox Environment. Beware, we have multiple instances, so access the instance with its URL where you have an invitation.
On this page, select Request Account.
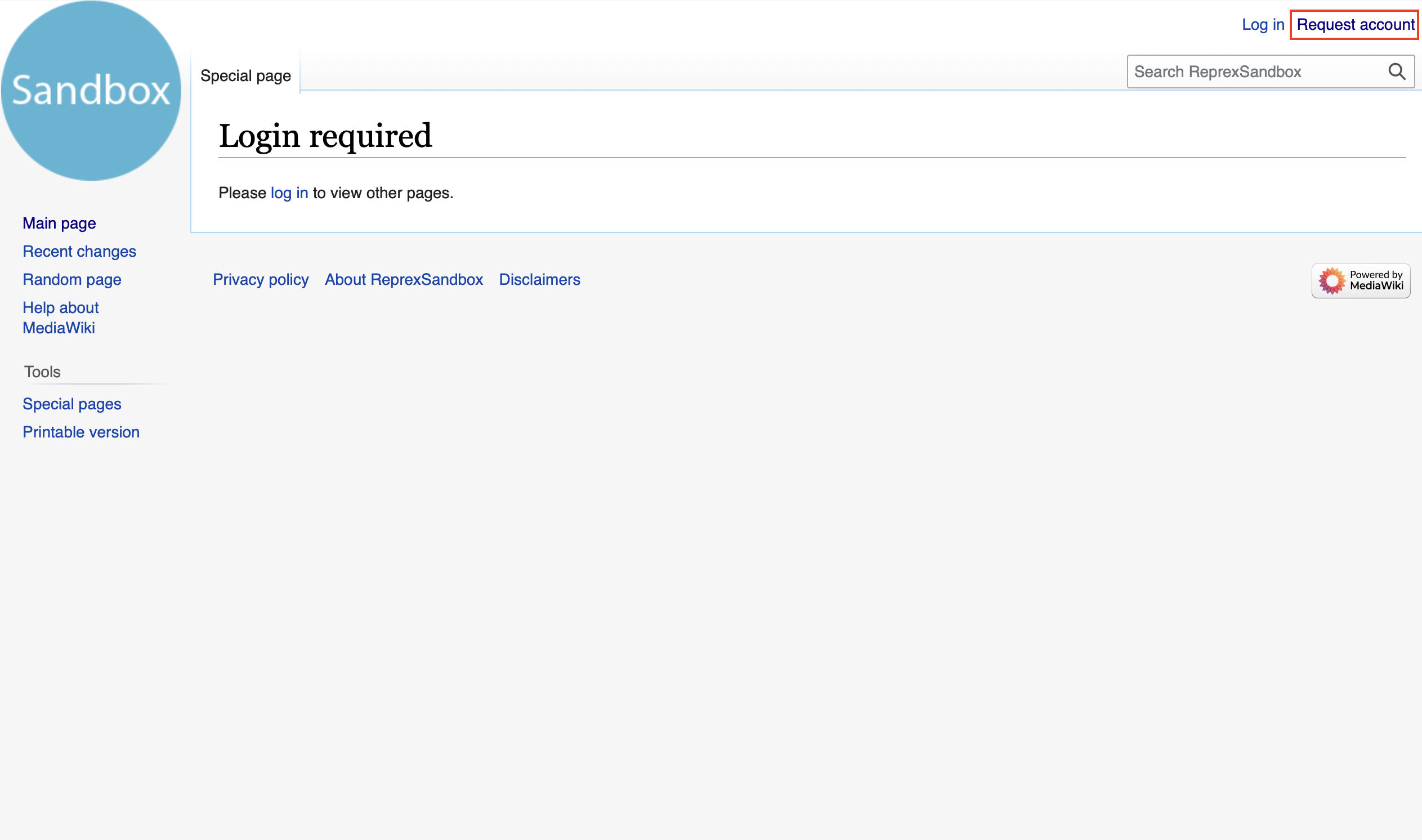
- On the next page, type in your chosen username and your email address. For a username, use a professional one that is similar to what you use on Keybase, Github, etc. Then confirm by clicking request account again.
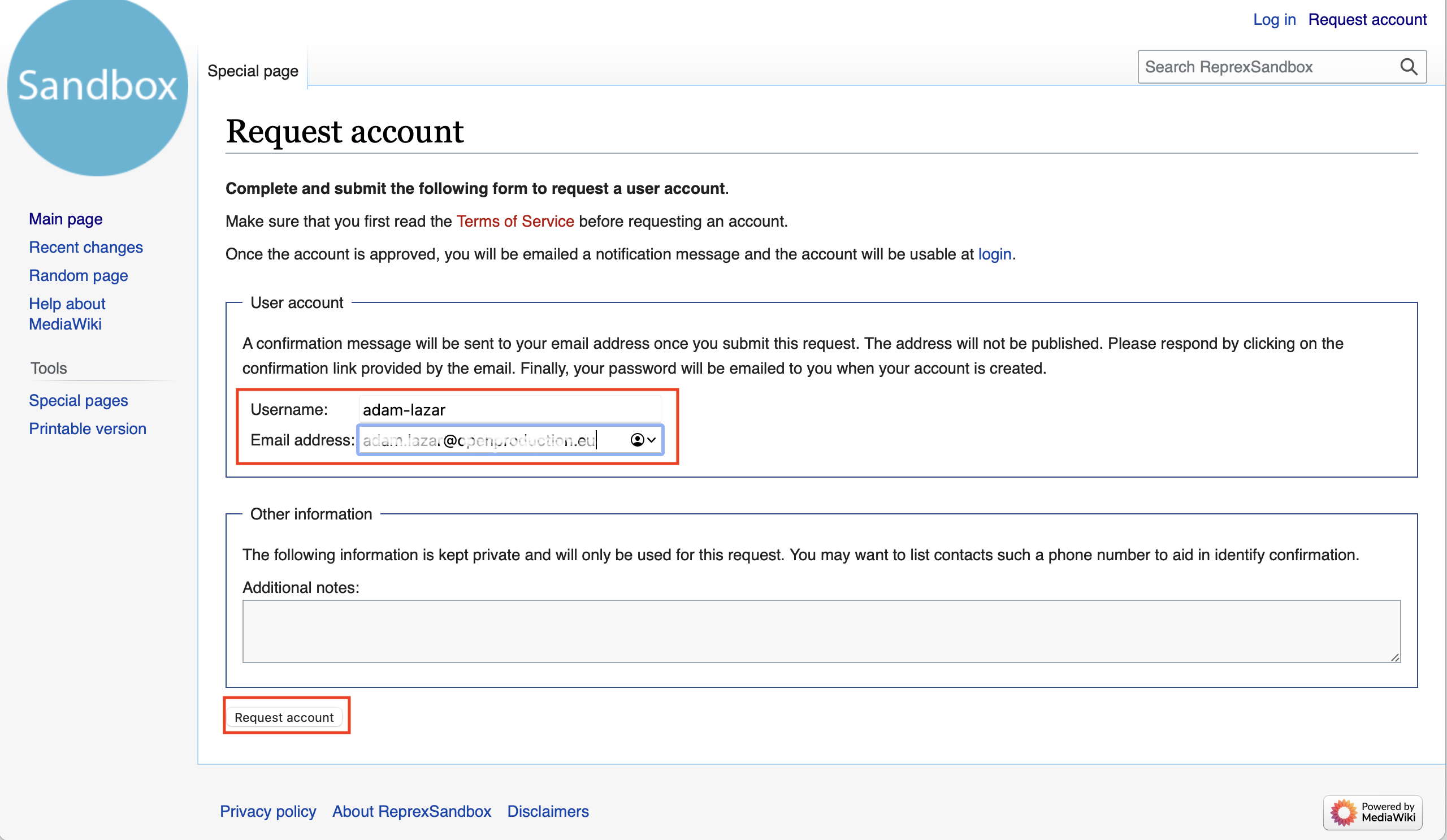
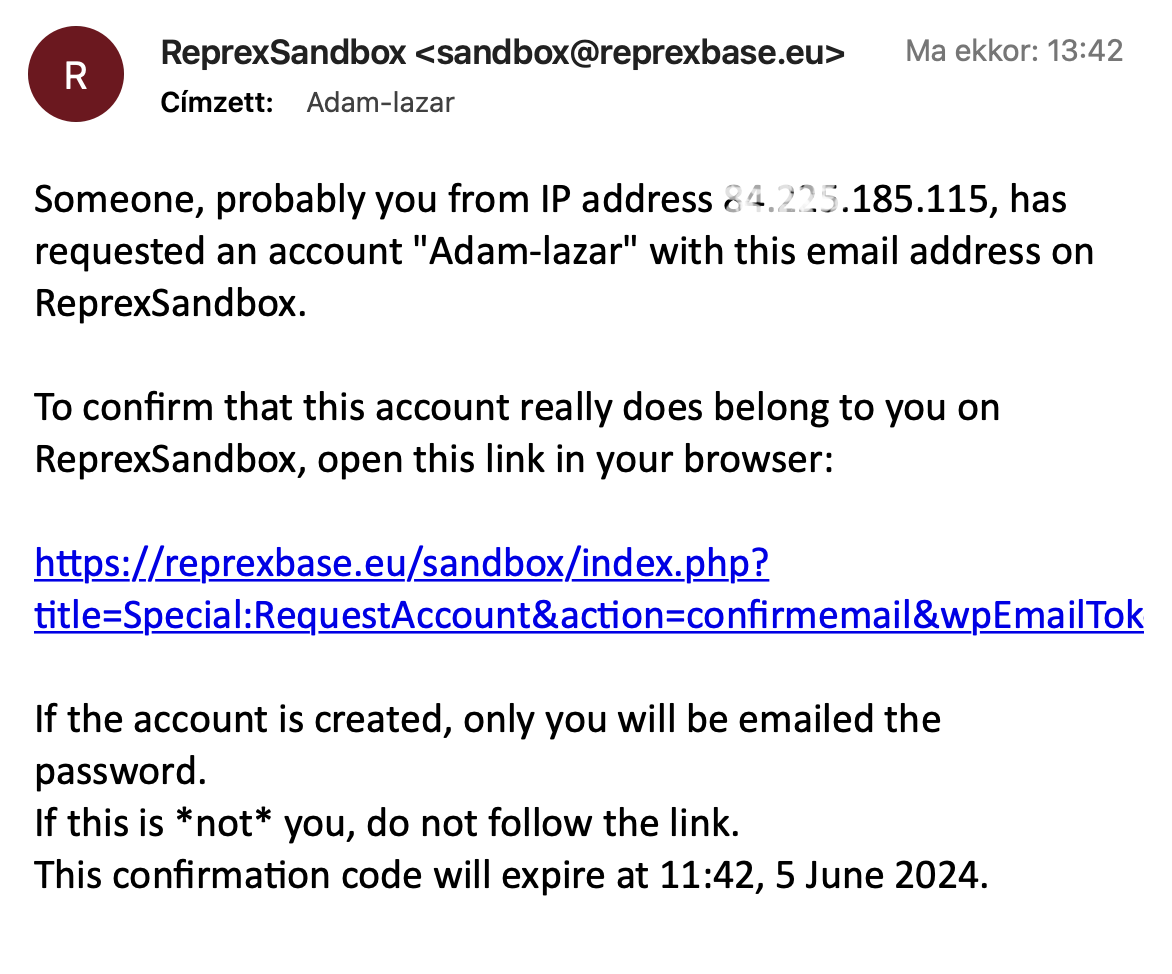
- Check your email inbox now. You should receive an email with a confirmation link. Click on this confirmation link. (The machine-generated email may easily go to the spam box.)
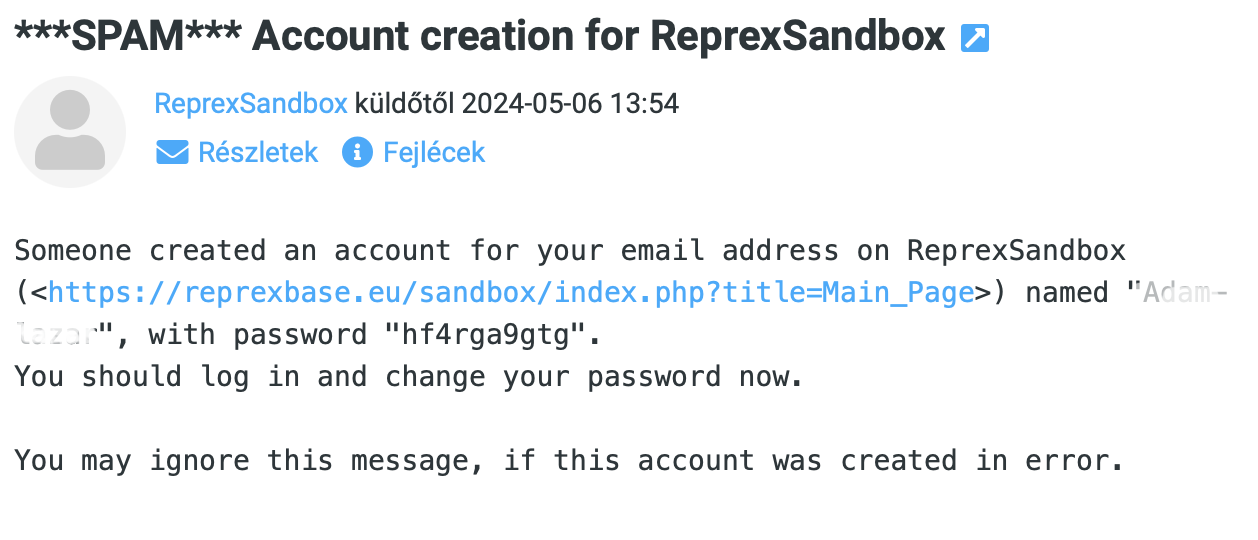
- After you confirm your account request, the administrators of the Wikibase instance will evaluate it. Then, you will receive another email with your login credentials, including your temporary password.
- Revisit the sandbox page and log in. On the login page, type your username and the temporary password you received, then click Log In. You will be automatically taken to the next page, where you must change your password by typing your new permanent password. Provide your new password, then confirm it.
- All done; you are now logged in to your account.
6.2 Editing data
6.3 Weaving Data Into the Knowledge Graph
Just because we edit data in a Wikibase instance, it will not necessarily be more usable than a spreadsheet or a simple local database. If we add 42 without a context, such as age or the number of tracks, these two numeric characters will be only literal numbers. We can increase knowledge by making every point of information a node in the knowledge graph, an edge where new information can flow in.
In Wikibase, we call these nodes entities. If we make Albert Einstein an entity instead of the string Albert Einstein, we will be able connect knowledge about his life, his scientific work, proofs, photographs of his lectures, and other forms of knowledge.
When we start importing information into a knowledge graph or begin editing and enriching information within the graph, we are faced with a crucial decision. We must determine which data points, such as cells in an original spreadsheet, or database table, or financial ledger, should be elevated to the status of nodes in the graph. These nodes, or entities, have the potential to develop their own relationships, thereby enriching the overall knowledge graph. Understanding this decision-making process empowers us to effectively utilize Wikibase for our data management needs.
6.3.1 Improving relational databases
When the aim is to improve the data quality, content, or timeliness of a relational database system, the first and most essential candidates to become entities are the database’s primary and secondary keys. To recall our simple example from Section 4.1,
| ID | Author | Title |
|---|---|---|
| My-01 | Martell, Yann (Q13914) | Life of Pi (Q374204) |
| … | … | … |
| My-42 | Adams, Douglas (Q42) | Hitchhiker’s Guide to the Galaxy Q25169) |
| … | … | … |
If you can connect your My-42 entry with Q25169 on Wikidata, you can import a wealth of information into your private catalogue. And if you add Q42 to the author Douglas Adams, you can import a lot of knowledge, for example, information about his other works or the end of the copyright protection term of these books, after which they will become public domain and free for copying and distribution.
Intuitively, in Wikibase, this means that we “conceptualise” authors and their books. The person known as Douglas Adams becomes a human, a creator, and a writer, with all the properties that writers have… such as books. The Hitchhiker’s Guide to the Galaxy will turn from string into the concept of a Book. As soon as we state that this is a book, not merely a text, we can start adding book-specific knowledge to the Hitchhiker's Guide to the Galaxy book entity: ISBN number, first publication date, translations. And what is most important, we can connect this entity with the author, Douglas Adams, who is no longer just one of the many people who are known by this name, but the person who wrote quiet humorous books.
Conceptualisation is possibly manually, as we have shown in Section 4.1; but usually we do this after data modelling with bulk importing. You tells us what is your data about: books and author, and we import them as Books and Authors, so that we can start to look for more information about these books and authors in various knowledge systems.
6.3.2 Improving spreadsheet databases
Smaller organisations often do not use relational databases; instead, they use Excel or OpenOffice spreadsheets maintained by workers, often for decades. Turning such spreadsheets into knowledge base elements is similar to working with a relational database, but sometimes, it is a smaller and more difficult task.
Well-organised spreadsheets can be good databases because spreadsheet applications like Excel, OpenOffice, or Google Spreadsheet allow the use of primary and secondary keys by connecting worksheets and the creation of pivot tables.
The key challenge with spreadsheets is identifying the Things that should become entities. What is your spreadsheet about? Buildings? Then, addresses and building names should become entities and nodes in the graph. Addresses keep changing, building geometries keep changing, and new additions are built or demolished. Street names change. Even city names change; cities merge and divide.